Memcached
Memcached é um sistema de cache de objetos distribuído de alto desempenho, utilizado em aplicações web dinâmicas para reduzir a carga no banco de dados. Ele armazena dados e objetos na memória RAM, diminuindo o número de consultas ao banco e acelerando sites orientados a dados. Baseia-se em um mapa hash de pares chave/valor. O daemon é escrito em C, mas os clientes podem ser implementados em várias linguagens, comunicando-se via protocolo memcached.
Neste artigo, focaremos no uso prático do memcached com Python. A instalação do servidor e do módulo python-memcached não será abordada.
1. Criando e Obtendo Valores
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
cliente.set('nome', 'joao')
resultado = cliente.get('nome')
print(resultado) # Saída: joao
O módulo python-memcached suporta clusters nativamente. Internamente, mantém uma lista de servidores onde a frequência de repetição é proporcional ao peso de cada host. Por exemplo:
# Host Peso
# 1.1.1.1 1
# 1.1.1.2 2
# 1.1.1.3 1
# Lista resultante na memória:
host_list = ["1.1.1.1", "1.1.1.2", "1.1.1.2", "1.1.1.3"]
2. Operações Comuns com python-memcached
add
Adiciona um par chave/valor. Se a chave já existir, lança uma exceção.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
cliente.add('nome', 'MARIA') # Se 'nome' já existir, ocorrerá erro
replace
Substitui o valor de uma chave existente. Se a chave não existir, lança exceção.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
cliente.replace('nome', 'carlos')
valor = cliente.get('nome')
print(valor) # Saída: carlos
set e set_multi
set define um par chave/valor; cria se não existir, atualiza se existir.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
cliente.set('nome', 'PAULA')
print(cliente.get('nome')) # Saída: PAULA
set_multi define vários pares de uma vez (dicionário).
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
dados = {'nome': 'PAULA', 'idade': '25'}
cliente.set_multi(dados)
print(cliente.get('nome'), cliente.get('idade'))
delete e delete_multi
delete remove um par específico.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
cliente.set('nome', 'joao')
print(cliente.get('nome')) # joao
cliente.delete('nome')
print(cliente.get('nome')) # None
delete_multi remove múltiplas chaves (lista).
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
dados = {'nome': 'ana', 'idade': '30'}
cliente.set_multi(dados)
cliente.delete_multi(['nome', 'idade'])
get e get_multi
get retorna o valor de uma chave. get_multi retorna um dicionário com várias chaves.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
dados = {'nome': 'carlos', 'idade': '28', 'sexo': 'M'}
cliente.set_multi(dados)
nome = cliente.get('nome')
outros = cliente.get_multi(['idade', 'sexo'])
print(nome, outros) # Saída: carlos {'sexo': 'M', 'idade': '28'}
append e prepend
append adiciona conteúdo ao final do valor atual.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
# Supondo que 'nome' exista com valor 'pedro'
cliente.append('nome', '-sufixo')
print(cliente.get('nome')) # pedro-sufixo
prepend insere conteúdo no início.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
# Supondo que 'nome' seja 'pedro-sufixo'
cliente.prepend('nome', 'prefixo-')
print(cliente.get('nome')) # prefixo-pedro-sufixo
decr e incr
incr incrementa o valor numérico em N (padrão 1). decr decrementa.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True)
cliente.set('contador', '10')
cliente.incr('contador')
print(cliente.get('contador')) # 11
cliente.decr('contador')
print(cliente.get('contador')) # 10
gets e cas
Evitam condições de corrida em operações de leitura-modificação-escrita. Exemplo: estoque de produto.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True, cache_cas=True)
cliente.set('estoque', '90000')
cliente.gets('estoque')
sucesso = cliente.cas('estoque', '89999')
print(sucesso) # True
Se outro cliente modificar o valor entre gets e cas, a operação falha.
import memcache
cliente = memcache.Client(['10.0.0.8:12000'], debug=True, cache_cas=True)
cliente.set('estoque', '90000')
cliente.gets('estoque')
cliente.decr('estoque') # Outra modificação
sucesso = cliente.cas('estoque', '89999')
print(sucesso) # False, pois o valor foi alterado
Redis
Redis é um sistema de armazenamento chave-valor avançado, semelhante ao Memcached, mas suporta tipos de dados mais ricos: strings, listas, conjuntos, conjuntos ordenados e hashes. Todas as operações são atômicas. Redis oferece persistência em disco, replicação mestre-escravo, e suporte a pub/sub.
Comparado ao Memcached, Redis permite estruturas de dados mais complexas e operações atômicas do lado do servidor, como interseção de conjuntos, classificação, etc.
Instalação e Conexão Básica
import redis
cliente = redis.Redis(host='10.0.0.8', port=6379)
cliente.set('nome', 'joao')
print(cliente.get('nome')) # b'joao' (bytes)
Pool de Conexões
Utilizar um pool evita o custo de abrir/fechar conexões repetidamente.
import redis
pool_conexao = redis.ConnectionPool(host='10.0.0.8', port=6379)
cliente = redis.Redis(connection_pool=pool_conexao)
cliente.set('idade', '30')
print(cliente.get('idade')) # b'30'
Pipelining
Executa múltiplos cmoandos de uma só vez, reduzindo latência.
import redis
pool = redis.ConnectionPool(host='10.0.0.8', port=6379)
r = redis.Redis(connection_pool=pool)
pipe = r.pipeline(transaction=True)
pipe.set('fruta', 'maca')
pipe.set('cor', 'vermelho')
pipe.execute()
print(r.get('fruta'), r.get('cor'))
Operações com Strings
Redis armazena strings binárias. Principais comandos:
set(name, value, ex=None, px=None, nx=False, xx=False)setnx(name, value)– cria apenas se não existir.setex(name, value, time)– com expiração em segundos.mset(mapping)– múltiplos valores.getset(name, value)– retorna o valor anterior e atualiza.getrange(key, start, end)– fatia a string (bytes).setrange(name, offset, value)– substitui parte da string.strlen(name)– comprimento em bytes.incr/decr– encremento/decrmeento.append(key, value)– concatena ao final.
Exemplos:
import redis
pool = redis.ConnectionPool(host='10.0.0.8', port=6379)
r = redis.Redis(connection_pool=pool)
# mset e mget
r.mset({'nome': 'ana', 'cidade': 'sp'})
valores = r.mget('nome', 'cidade')
print(valores) # [b'ana', b'sp']
# getset
antigo = r.getset('nome', 'MARIA')
print(antigo) # b'ana'
print(r.get('nome')) # b'MARIA'
# getrange
r.set('palavra', 'python')
print(r.getrange('palavra', 1, 3)) # b'yth'
# setrange
r.setrange('palavra', 0, 'Java')
print(r.get('palavra')) # b'Javathon'
# incr/decr
r.set('contador', 100)
r.incr('contador')
print(r.get('contador')) # b'101'
r.decr('contador', 5)
print(r.get('contador')) # b'96'
# append
r.append('palavra', ' é legal')
print(r.get('palavra')) # b'Java é legal'
Operações com Hashes
Armazena pares campo-valor dentro de uma chave.
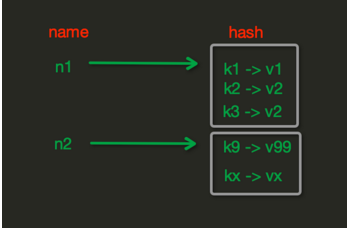
hset(name, key, value)hmset(name, mapping)hget(name, key)hmget(name, keys)hgetall(name)hlen(name),hkeys(name),hvals(name)hexists(name, key)hdel(name, *keys)hincrby(name, key, amount)hincrbyfloat(name, key, amount)hscan(name, cursor=0, match=None, count=None)hscan_iter(name, match=None, count=None)
Exemplo:
import redis
pool = redis.ConnectionPool(host='10.0.0.8', port=6379)
r = redis.Redis(connection_pool=pool)
r.hset('usuario:1000', 'nome', 'joao')
r.hset('usuario:1000', 'idade', 30)
print(r.hget('usuario:1000', 'nome')) # b'joao'
print(r.hgetall('usuario:1000')) # {b'nome': b'joao', b'idade': b'30'}
# scan iterativo
for campo in r.hscan_iter('usuario:1000'):
print(campo)
Operações com Listas
Listas são sequências ordenadas.
lpush(name, *values)– insere à esquerda.rpush(name, *values)– insere à direita.lpushx(name, value)– só se a lista existir.llen(name)linsert(name, where, refvalue, value)– BEFORE ou AFTER.lset(name, index, value)lrem(name, value, num)lpop(name),rpop(name)lindex(name, index)lrange(name, start, end)ltrim(name, start, end)rpoplpush(src, dst)blpop(keys, timeout),brpop(keys, timeout)brpoplpush(src, dst, timeout)
Exemplo:
import redis
pool = redis.ConnectionPool(host='10.0.0.8', port=6379)
r = redis.Redis(connection_pool=pool)
r.lpush('lista', 'c', 'b', 'a') # ordem: a, b, c (esquerda)
r.rpush('lista', 'd', 'e') # ordem: a, b, c, d, e
print(r.lrange('lista', 0, -1)) # [b'a', b'b', b'c', b'd', b'e']
r.lpop('lista') # remove 'a'
print(r.lrange('lista', 0, -1)) # [b'b', b'c', b'd', b'e']
# Iteração personalizada (incremental)
def iterar_lista(nome):
tamanho = r.llen(nome)
for i in range(tamanho):
yield r.lindex(nome, i)
for item in iterar_lista('lista'):
print(item)
Operações com Conjuntos (Sets)
Conjuntos não permitem elementos duplicados.
sadd(name, *values)scard(name)sdiff(keys, *args)sdiffstore(dest, keys, *args)sinter(keys, *args)sinterstore(dest, keys, *args)sismember(name, value)smembers(name)smove(src, dst, value)spop(name)srandmember(name, numbers)srem(name, *values)sunion(keys, *args)sunionstore(dest, keys, *args)sscanesscan_iter
Exemplo:
import redis
pool = redis.ConnectionPool(host='10.0.0.8', port=6379)
r = redis.Redis(connection_pool=pool)
r.sadd('conjunto1', 'a', 'b', 'c')
r.sadd('conjunto2', 'c', 'd', 'e')
print(r.sinter('conjunto1', 'conjunto2')) # {b'c'}
print(r.sunion('conjunto1', 'conjunto2')) # {b'a', b'b', b'c', b'd', b'e'}
Conjuntos Ordenados (Sorted Sets)
Cada elemento possui uma pontuação (score) usada para ordenação.
zadd(name, *args, **kwargs)zrange(name, start, end, desc=False, withscores=False)zrevrange(name, start, end, withscores=False)zrangebyscore(name, min, max, start=None, num=None, withscores=False)zrevrangebyscore(name, max, min, ...)zrank(name, value),zrevrankzrangebylex(name, min, max, start=None, num=None)zrem(name, *values)zcard(name),zcount(name, min, max)zincrby(name, value, amount)zremrangebyrank,zremrangebyscore,zremrangebylexzscore(name, value)zinterstore(dest, keys, aggregate=None)zunionstore(dest, keys, aggregate=None)zscan,zscan_iter
Exemplo:
import redis
pool = redis.ConnectionPool(host='10.0.0.8', port=6379)
r = redis.Redis(connection_pool=pool)
r.zadd('ranking', {'joao': 100, 'maria': 200, 'carlos': 150})
print(r.zrange('ranking', 0, -1, withscores=True))
# [(b'joao', 100.0), (b'carlos', 150.0), (b'maria', 200.0)]
print(r.zrank('ranking', 'maria')) # 2 (0-based)
r.zincrby('ranking', 50, 'joao')
print(r.zscore('ranking', 'joao')) # 150.0
Outras Operações Úteis
delete(*names)– remove qualquer tipo de chave.exists(name)expire(name, time)– define tempo de expiração.rename(src, dst)move(name, db)randomkey()type(name)
import redis
pool = redis.ConnectionPool(host='10.0.0.8', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('chave', 'valor')
print(r.exists('chave')) # True
r.expire('chave', 60) # expira em 60 segundos
print(r.type('chave')) # b'string'
Publicação/Subscrição (Pub/Sub)
Redis suporta o padrão publicador/assinante.

Exemplo de uma classe auxiliar RedisHelper:
# redis_helper.py
import redis
class RedisHelper:
def __init__(self):
self.conexao = redis.Redis(host='10.211.55.4')
self.canal_sub = 'fm104.5'
self.canal_pub = 'fm104.5'
def publicar(self, mensagem):
self.conexao.publish(self.canal_pub, mensagem)
return True
def assinar(self):
pub = self.conexao.pubsub()
pub.subscribe(self.canal_sub)
pub.parse_response()
return pub
Assinante:
from redis_helper import RedisHelper
helper = RedisHelper()
sub = helper.assinar()
while True:
mensagem = sub.parse_response()
print(mensagem)
Publicador:
from redis_helper import RedisHelper
helper = RedisHelper()
helper.publicar('Olá do publicador')
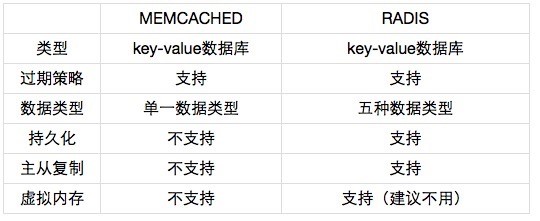
Comparação entre Memcached e Redis
| Característica | Memcached | Redis |
|---|---|---|
| Performance | Alta, usa múltiplos núcleos | Alta, mas tende a usar um único núcleo; para dados pequenos é mais rápido por núcleo |
| Tipos de dados | Apenas strings | Strings, listas, conjuntos, conjuntos ordenados, hashes |
| Persistência | Não nativa | Suporte a persistência em disco (RDB, AOF) |
| Operações atômicas | Básicas | Operações complexas do lado do servidor |
| Replicação | Não nativa | Mestre-escravo, alta disponibilidade |
| Uso de memória | Eficiente para valores grandes (>100KB) | Eficiente para valores pequenos com estruturas compactas |
Escolha: Para dados grandes (>100KB) e simplicidade, prefira Memcached. Para estruturas complexas, persistência e operações atômicas, Redis é a melhor opção.